
 雨落烟波起
雨落烟波起 -
解决办法:
1、首先打开程序,在wp-includes目录下找到functions.php文件;
2、然后用记事本打开或者是用dreamweaver 打开,用dreamweaver进行编辑,打开functions.php文件,找到function do_robots() ,大概在1070行左右,可以看到系统默认的robots.txt文件的定义规则。
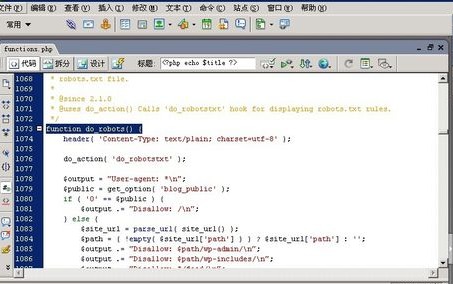
3、按照上面的规则样式来重新编写,将网站需要添加的内容添加到这段代码里面。
4、添加好之后然后点击保存,这时候就可以打开网站查看网站robots.txt是否完整了
 CatMTan
CatMTan -
不显示说明你没有robots.txt这个文件呀!
从本地新建一个robots.txt文件,注意!是txt的哦!
如果你会写就自己写,不会写就复制这个内容到这个文件中
User-agent:*
Allow:/
Disallow:/wp-admin
Disallow:/wp-includes
Disallow:/wp-content/plugins
Disallow:/wp-content/cache
Disallow:/wp-content/themes
Disallow:/wp-*
Disallow:/wp-login.php
Sitemap:这里写你的网站地图URL
把这个文件上传到你的根目录
 永节芜贱买断之之耻
永节芜贱买断之之耻
-
1、首先打开程序,在wp-includes目录下找到functions.php文件
2、然后用记事本打开或者是用dreamweaver 打开,这里用dreamweaver进行编辑,打开functions.php文件,找到function do_robots() ,大概在1070行左右,可以看到系统默认的robots.txt文件的定义规则。
3、按照上面的规则样式来重新编写,将网站需要添加的内容添加到这段代码里面。
添加好之后然后点击保存,这时候就可以打开你的网站查看网站robots.txt是否完整了。
案例:运营人博客 www.wzyunying.com
 ardim
ardim -
你可以自己编写,然后上传到网站的根目录。
相关推荐
什么是robots.txt文件
应该是robots.txt文件吧, robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。Robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。robots.txt 是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。 当一个搜索机器人robots(有的叫搜索蜘蛛或者爬虫)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索引擎爬虫就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索引擎爬虫就沿着链接抓取。robots.txt 文件限制抓取网络的搜索引擎爬虫对您的网站的访问。这些搜索引擎爬虫是自动的,它们在访问任意网站的网页之前,都会查看是否存在阻止它们访问特定网页的 robots.txt 文件。(虽然某些搜索引擎爬虫可能会以不同的方式解释 robots.txt 文件中的指令,但所有正规的搜索引擎爬虫都会遵循这些指令。然而,robots.txt 不是强制执行的,一些垃圾信息发送者和其他麻烦制造者可能会忽略它。因此,我们建议对机密信息采用密码保护。) 只有当您的网站中包含您不想让搜索引擎编入索引的内容时,才需要使用 robots.txt 文件。如果您希望搜索引擎将网站上的所有内容编入索引,则不需要 robots.txt 文件(甚至连空的 robots.txt 文件也不需要)。 为了能使用 robots.txt 文件,您必须要有对您网站的根目录的访问权限(如果您不能确定是否有该权限,请与您的网络托管商核实)。如果您没有对网站的根目录的访问权限,可以使用robots元标记来限制访问。2023-07-25 11:00:521
如何访问b站的robots.txt?
在网络爬虫领域,robots.txt是一个非常重要的文件,它指定了网站上哪些页面可以被爬取,哪些页面不能被爬取。b站也有一个robots.txt文件,用于指定其网站上的爬取规则。下面是访问b站的robots.txt文件的步骤:1.打开您的网页浏览器,如Chrome,Firefox等,输入b站的网址“www.bilibili.com”。2.在浏览器地址栏的末尾输入“/robots.txt”,即“www.bilibili.com/robots.txt”,然后按下回车键。3.您现在应该可以在浏览器中看到b站的robots.txt文件。该文件包含了一些指令,告诉网络爬虫哪些页面可以被爬取,哪些页面不能被爬取。4.在该文件中,您可以找到类似于“User-agent: *”和“Disallow: /video/”等指令。这些指令告诉网络爬虫,在爬取b站网站时应该遵循哪些规则,例如不要爬取/video/路径下的页面。总之,访问b站的robots.txt文件可以让您了解网站的爬取规则,这对于开发人员、SEO优化人员等非常有用。但请注意,访问robots.txt文件并不意味着您可以随意爬取网站的内容。如果您需要爬取b站的内容,请务必遵循其robots.txt文件中的规则,并获得网站所有者的明确许可。2023-07-25 11:00:591
怎样查看网站robots.txt内容
robots.txt文件应该放在网站根目录下,用好robots是很容易为你网站提权的。robots.txt其实就是个记事本文件,这个文件应该放到网站的根目录如想让蜘蛛抓取你的所有页面,可以上传一个空的记事本文件命名为“robots.txt”上传到根目录即可2023-07-25 11:01:061
如何写robots.txt文件才能集中网站权重
如何写robots.txt文件才能集中网站权重?一:什么是robots协议robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也就是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不希望被抓取。u2022 Robots协议是网站国际互联网界通行的道德规范,其目的是保护网站数据和敏感信息、确保用户个人信息和隐私不被侵犯。u2022 因其不是命令,是一种单方面协议,故需要搜索引擎自觉遵守。淘宝利用robots屏蔽了百度蜘蛛的抓取淘宝的robots协议 二:robots.txt放置位置robots.txt文件应该放置在网站根目录下。例如,当spider访问一个网站(比如 http://www.taobao.com)时,首先会检查该网站中是否存在http://www.taobao.com/robots.txt这个文件,如果 Spider找到这个文件,它就会根据这个文件的内容,来确定它访问权限的范围。 三:robots.txt文件的写法操作步骤:1.新建一个文本文档,命名为robots.txt2.开始写robotsUser-agent: * (*针对所有搜索引擎)Disallow: / (禁止爬取所有页面,/代表目录)Disallow: /admin/ (禁止抓取admin目录)Disallow: /admin (禁止抓取包含admin的路径)Allow: /admin/s3.html (允许抓取admin目录下s3.html文件)一个“/”表示路径,两个“/”表示文件夹Allow: /admin/php/ (允许抓取admin下面的php文件的所有内容)Disallow: /.css$ (禁止抓取所有带.css的文件)sitemap:*** 注意:u2022 冒号后面有空格,空格后面都有/(都要以/开头),开头第一个字母大写u2022 因为搜索引擎蜘蛛来抓取网站的时候最先看的就robots文件,我们把网站地图的地址放到robots协议中有利于搜索引擎蜘蛛的抓取,从而提高网站的收录。2023-07-25 11:01:211
如何设置robots.txt
robots.txt的使用方法和详细解释 robots.txt对于大多数有网站优化经验的朋友来说并不算太陌生,用过的朋友肯定会有感受,设置好robots.txt对网站优化来说利远远大于弊。今天彭宇诚就与大家分享一下robots.txt的使用方法,希望对大家有所帮助。 我们先来认识一下什么是robots.txt? 我理解的是robots.txt是通过代码控制搜索引擎蜘蛛索引的一个手段,以便减轻网站服务器的带宽使用率,从而让网站的空间更稳定,同时也可以提高网站其他页面的索引效率,提高网站收录。 下面我们再来熟悉一下怎样使用robots.txt? 首先,我们需要创建一个robots.txt文本文件,然后在文档内设置好代码,告诉搜索引擎我网站的哪些文件你不能访问。然后上传到网站根目录下面,因为当搜索引擎蜘蛛在索引一个网站时,会先爬行查看网站根目录下是否有robots.txt文件。 robots.txt文件内的代码书写规范我们也要注意,其中User-agent:*是必须存在的,表示对所有搜索引擎蜘蛛有效。Disallow:是说明不允许索引哪些文件夹2023-07-25 11:01:294
robots.txt文件要怎么写
大家先了解下robots.txt文件是什么,有什么作用。搜索引擎爬去我们页面的工具叫做搜索引擎机器人,也生动的叫做“蜘蛛”蜘蛛在爬去网站页面之前,会先去访问网站根目录下面的一个文件,就是robots.txt。这个文件其实就是给“蜘蛛”的规则,如果没有这个文件,蜘蛛会认为你的网站同意全部抓取网页。Robots.txr文件是一个纯文本文件,可以告诉蜘蛛哪些页面可以爬取(收录),哪些页面不能爬取。举个例子:建立一个名为robots.txt的文本文件,然后输入User-agent: * 星号说明允许所有搜索引擎收录Disallow: index.php? 表示不允许收录以index.php?前缀的链接,比如index.php?=865Disallow: /tmp/ 表示不允许收录根目录下的tmp目录,包括目录下的文件,比如tmp/232.html具体使用方法百度和谷歌都有解释,百度http://www.baidu.com/search/robots.htmlRobots.txt文件可以帮助我们让搜索引擎删除已收录的页面,大概需要30-50天。2023-07-25 11:01:361
robots.txt应该放在什么地方
您好楼主:robots.txt是要放到根目录下面的。所谓的根目录就是你的网站程序所在的那个目录,一般的根目录貌似都是个叫WEB或者www文件夹robots.txt文件必须驻留在域的根目录,并且必须命名为“robots.txt”。位于子目录中的robots.txt文件无效,因为漫游器只在域的根目录这个文件。例如,http://www.baidu.com/robots.txt是有效位置。但是,http://www.baidu.com/mysite/robots.txt不是。如果您没有访问域的根目录,可以使用限制访问robots元标记。2023-07-25 11:01:431
robots.txt的写法
robots.txt的写法是做seo的人员必须知道的(什么是robots.txt),但该如何写,禁止哪些、允许哪些,这就要我们自己设定了。百度蜘蛛是一机器,它只认识数字、字母和汉字,而其中robots.txt就是最重要也是最开始和百度“对话”的内容。当我们的网站在没有建好的时候,我们不希望百度来抓取我们的网站,往往有人会禁止百度来抓取。但是,这种做法是非常不好的,这样会让百度蜘蛛很难再来到你的网站了。所以,我们必须现在本地搭建网站,等一切都搞好以后,再去买域名、空间,要不,一个网站的反复修改,会对你的网站有一定的不利影响。我们的网站起初的robots.txt写法如下:User-agent: *Disallow: /wp-admin/Disallow: /wp-includes/User-agent: * 的意思是,允许所以引擎抓取。而Disallow: /wp-admin/和Disallow: /wp-includes/,则是禁止百度抓取我们的隐私,包括用户密码、数据库等。这样的写法既保护了我们的隐私,也让百度蜘蛛的抓取最大化。如果,你想禁止百度蜘蛛抓取某一个页面,比如123.html,那就加一句代码“Disallow: /123.html/”即可。robots.txt写好后,只需要上传到网站的根目录下即可。2023-07-25 11:01:501
robot.txt的使用技巧
每当用户试图访问某个不存在的URL时,服务器都会在日志中记录404错误(无法找到文件)。每当搜索蜘蛛来寻找并不存在的robots.txt文件时,服务器也将在日志中记录一条404错误,所以你应该在网站中添加一个robots.txt。网站管理员必须使搜索引擎机器人程序远离服务器上的某些目录,以保证服务器性能。比如:大多数网站服务器都有程序储存在“cgi-bin”目录下,因此在robots.txt文件中加入“Disallow: /cgi-bin”是个好主意,这样能够避免所有程序文件都被蜘蛛索引,以达到节省服务器资源的效果。一般网站中不需要蜘蛛抓取的文件有:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等等。下面是VeryCMS里的robots.txt文件:User-agent: *Disallow: /admin/ 后台管理文件Disallow: /require/程序文件Disallow: /attachment/ 附件Disallow: /images/ 图片Disallow: /data/数据库文件Disallow: /template/ 模板文件Disallow: /css/ 样式表文件Disallow: /lang/ 编码文件Disallow: /script/脚本文件Disallow: /js/js文件如果你的网站是动态网页,并且你为这些动态网页创建了静态副本,以供搜索蜘蛛更容易抓取。那么你需要在robots.txt文件里设置避免动态网页被蜘蛛索引,以保证这些网页不会被视为是网站重复的内容。robots.txt文件里还可以直接包括在sitemap文件的链接。就像这样:Sitemap: http://www.***.com/sitemap.xml目 前对此表示支持的搜索引擎公司有Google, Yahoo, Ask and MSN。而中文搜索引擎公司,显然不在这个圈子内。这样做的好处就是,站长不用到每个搜索引擎的站长工具或者相似的站长部分,去提交自己的sitemap文件,搜索引擎的蜘蛛自己就会抓取robots.txt文件,读取其中的sitemap路径,接着抓取其中相链接的网页。合理使用robots.txt文件还能避免访问时出错。比如,不能让搜索者直接进入购物车页面。因为没有理由使购物车被收录,所以你可以在robots.txt文件里设置来阻止搜索者直接进入购物车页面。2023-07-25 11:01:571
静态站点页面robots.txt写法
Robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不能被搜索引擎的漫游器获取的,哪些是可以被(漫游器)获取的。一个典型的文件内容如下: User-agent: Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /private/ 因为一些系统中的URL是大小写敏感的,所以Robots.txt的文件名应统一为小写,即robots.txt。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据。 Robots.txt协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。注意Robots.txt是用字符串比较来确定是否获取URL,所以目录末尾有和没有斜杠“/”这两种表示是不同的URL,也不能用"Disallow: .gif"这样的通配符。 其他的影响搜索引擎的行为的方法包括使用robots元数据:这个协议也不是一个规范,而只是约定俗成的,通常搜索引擎会识别这个元数据,不索引这个页面,以及这个页面的链出页面。 robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。 当一个搜索机器人(有的叫搜索蜘蛛)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取。 另外,robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。 robots.txt写作语法 首先,我们来看一个robots.txt范例:http://www.csswebs.org/robots.txt 访问以上具体地址,我们可以看到robots.txt的具体内容如下: # Robots.txt file from http://www.csswebs.org # All robots will spider the domain User-agent: * Disallow: 以上文本表达的意思是允许所有的搜索机器人访问www.csswebs.org站点下的所有文件。 具体语法分析:其中#后面文字为说明信息;User-agent:后面为搜索机器人的名称,后面如果是*,则泛指所有的搜索机器人;Disallow:后面为不允许访问的文件目录。 下面,我将列举一些robots.txt的具体用法: 允许所有的robot访问 User-agent: * Disallow: 或者也可以建一个空文件 “/robots.txt” file 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 禁止所有搜索引擎访问网站的几个部分(下例中的01、02、03目录) User-agent: * Disallow: /01/ Disallow: /02/ Disallow: /03/ 禁止某个搜索引擎的访问(下例中的BadBot) User-agent: BadBot Disallow: / 只允许某个搜索引擎的访问(下例中的Crawler) User-agent: Crawler Disallow: User-agent: * Disallow: / 另外,我觉得有必要进行拓展说明,对robots meta进行一些介绍: Robots META标签则主要是针对一个个具体的页面。和其他的META标签(如使用的语言、页面的描述、关键词等)一样,Robots META标签也是放在页面的<head></head>中,专门用来告诉搜索引擎ROBOTS如何抓取该页的内容。 Robots META标签的写法: Robots META标签中没有大小写之分,name=”Robots”表示所有的搜索引擎,可以针对某个具体搜索引擎写为name=”BaiduSpider”。 content部分有四个指令选项:index、noindex、follow、nofollow,指令间以“,”分隔。 INDEX 指令告诉搜索机器人抓取该页面; FOLLOW 指令表示搜索机器人可以沿着该页面上的链接继续抓取下去; Robots Meta标签的缺省值是INDEX和FOLLOW,只有inktomi除外,对于它,缺省值是INDEX,NOFOLLOW。 这样,一共有四种组合: <META NAME=”ROBOTS” CONTENT=”INDEX,FOLLOW”> <META NAME=”ROBOTS” CONTENT=”NOINDEX,FOLLOW”> <META NAME=”ROBOTS” CONTENT=”INDEX,NOFOLLOW”> <META NAME=”ROBOTS” CONTENT=”NOINDEX,NOFOLLOW”> 其中 <META NAME=”ROBOTS” CONTENT=”INDEX,FOLLOW”>可以写成<META NAME=”ROBOTS” CONTENT=”ALL”>; <META NAME=”ROBOTS” CONTENT=”NOINDEX,NOFOLLOW”>可以写成<META NAME=”ROBOTS” CONTENT=”NONE”> 目前看来,绝大多数的搜索引擎机器人都遵守robots.txt的规则,而对于Robots META标签,目前支持的并不多,但是正在逐渐增加,如著名搜索引擎GOOGLE就完全支持,而且GOOGLE还增加了一个指令“archive”,可以限制GOOGLE是否保留网页快照。例如: <META NAME=”googlebot” CONTENT=”index,follow,noarchive”> 表示抓取该站点中页面并沿着页面中链接抓取,但是不在GOOLGE上保留该页面的网页快照。2023-07-25 11:02:212
如何使用robots.txt禁止搜索引擎收录~?!
关于robots.txt一般站长需要注意以下几点:如果你的站点对所有搜索引擎公开,则不用做这个文件或者robots.txt为空就行。必须命名为:robots.txt,都是小写,robot后面加"s"。robots.txt必须放置在一个站点的根目录下。如:通过http://www.seowhy.com/robots.txt可以成功访问到,则说明本站的放置正确。一般情况下,robots.txt里只写着两个函数:User-agent和Disallow。观察这个页面并修改为自己的:http://www.seowhy.com/robots.txt有几个禁止,就得有几个Disallow函数,并分行描述。至少要有一个Disallow函数,如果都允许收录,则写:Disallow:,如果都不允许收录,则写:Disallow:/(注:只是差一个斜杆)。补充说明:User-agent:*星号说明允许所有搜索引擎收录Disallow:/search.html说明http://www.seowhy.com/search.html这个页面禁止搜索引擎抓取。Disallow:/index.php?说明类似这样的页面http://www.seowhy.com/index.php?search=%E5%A5%BD&action=search&searchcategory=%25禁止搜索引擎抓取。2023-07-25 11:02:291
登录网站出现由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面,怎么办
1、修改robots文件,取消该页面的屏蔽,robots的标准写法百度百科里有详细介绍:网页链接2、在百度站长平台(已更名为百度资源平台)更新网站robots,过一段时间,您的这个网站就会被正常抓取收录了。2023-07-25 11:02:373
怎样解决robots.txt文件存在的限制指令
由于该网站的robots.txt文件存在限制指令的解决办法1.找到根目录下的robots.txt文件,去掉这一句disallow:/,解除屏蔽抓取;2.下面一步很关键,就是到站长平台下去更新robots文件,告诉搜索引擎你的网站已经对它解除了屏蔽,可以来抓取我的网页内容了,主动对搜索引擎示好,快照更新过来之后,现象就会消失了。2023-07-25 11:02:491
如何使用robots.txt控制网络蜘蛛访问
网络蜘蛛进入一个网站,一般会访问一个特殊的文本文件Robots.txt,这个文件一般放在网站服务器的根目录下。网站管理员可以通过robots.txt来定义哪些目录网络蜘蛛不能访问,或者哪些目录对于某些特定的网络蜘蛛不能访问。例如有些网站的可执行文件目录和临时文件目录不希望被搜索引擎搜索到,那么网站管理员就可以把这些目录定义为拒绝访问目录。Robots.txt语法很简单,例如如果对目录没有任何限制,可以用以下两行来描述:User-agent: *Disallow当然,Robots.txt只是一个协议,如果网络蜘蛛的设计者不遵循这个协议,网站管理员也无法阻止网络蜘蛛对于某些页面的访问,但一般的网络蜘蛛都会遵循这些协议,而且网站管理员还可以通过其它方式来拒绝网络蜘蛛对某些网页的抓取。2023-07-25 11:03:151
Robots.txt文件是什么文件,可以删掉吗
可以删掉,这是规定搜索引擎的网页机器人的动作的文件。删除后就不限制机器人抓取你的网页,也就是说任何网页都能抓2023-07-25 11:03:221
网站下面没有robots.txt怎么办
由于该网站的robots.txt文件存在限制指令的解决办法1.找到根目录下的robots.txt文件,去掉这一句disallow:/,解除屏蔽抓取;2.下面一步很关键,就是到站长平台下去更新robots文件,告诉搜索引擎你的网站已经对它解除了屏蔽,可以来抓取我的网页内容了,主动对搜索引擎示好,快照更新过来之后,现象就会消失了。2023-07-25 11:03:412
如何设置robots.txt禁止或只允许搜索引擎抓取特定目录?
网站的robots.txt文件一定要存放在网站的根目录。搜索引擎来网站抓取内容的时候,首先会访问你网站根目录下的一个文本文件robots.txt,搜索引擎机器人通过robots.txt里的说明,来理解该网站是否可以全部抓取,或只允许部分抓取。注意:网站的robots.txt文件一定要存放在网站的根目录。robots.txt文件举例说明禁止所有搜索引擎访问网站的任何内容User-agent: *Disallow: / 禁止所有搜索引擎抓取某些特定目录User-agent: *Disallow: /目录名1/Disallow: /目录名2/Disallow: /目录名3/ 允许访问特定目录中的部分urlUser-agent: *Allow: /158Allow: /joke 禁止访问网站中所有的动态页面User-agent: *Disallow: /*?*仅允许百度抓取网页和gif格式图片,不允许抓取其他格式图片User-agent: BaiduspiderAllow: /*.gif$Disallow: /*.jpg$Disallow: /*.jpeg$Disallow: /*.png$Disallow: /*.bmp$ 1.屏蔽404页面Disallow: /404.html 2.屏蔽死链原来在目录为/158下的所有链接,因为目录地址的改变,现在都变成死链接了,那么我们可以用robots.txt把他屏蔽掉。Disallow: /158/ 3.屏蔽动态的相似页面假设以下这两个链接,内容其实差不多。/XXX?123/123.html我们要屏掉/XXX?123 页面,代码如下:Disallow: /XXX? 4.告诉搜索引擎你的sitemap.xml地址2023-07-25 11:03:501
如何利用robots.txt对wordpress博客进行优化
一、先来普及下robots.txt的概念: robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不能被搜索引擎的漫游器获取的,哪些是可以被(漫游器)获取的。这个文件用于指定spider在您网站上的抓取范围,一定程度上保护站点的安全和隐私。同时也是网站优化利器,例如屏蔽捉取站点的重复内容页面。 robots.txt目前并不是一种标准,只是一种协议!所以现在很多搜索引擎对robots.txt里的指令参数都有不同的看待。 二、使用robots.txt需要注意的几点地方: 1、指令区分大小写,忽略未知指令,下图是本博客的robots.txt文件在Google管理员工具里的测试结果; 2、每一行代表一个指令,空白和隔行会被忽略; 3、“#”号后的字符参数会被忽略; 4、有独立User-agent的规则,会排除在通配“*”User agent的规则之外; 5、可以写入sitemap文件的链接,方便搜索引擎蜘蛛爬行整站内容。 6、尽量少用Allow指令,因为不同的搜索引擎对不同位置的Allow指令会有不同看待。 三、Wordpress的robots.txt优化设置 1、User-agent: * 一般博客的robots.txt指令设置都是面对所有spider程序,用通配符“*”即可。如果有独立User-agent的指令规则,尽量放在通配“*”User agent规则的上方。 2、Disallow: /wp-admin/ Disallow: /wp-content/ Disallow: /wp-includes/ 屏蔽spider捉取程序文件,同时也节约了搜索引擎蜘蛛资源。 3、Disallow: /*/trackback 每个默认的文章页面代码里,都有一段trackback的链接,如果不屏蔽让蜘蛛去捉取,网站会出现重复页面内容问题。 4、Disallow: /feed Disallow: /*/feed Disallow: /comments/feed 头部代码里的feed链接主要是提示浏览器用户可以订阅本站,而一般的站点都有RSS输出和网站地图,故屏蔽搜索引擎捉取这些链接,节约蜘蛛资源。 5、Disallow: /?s=* Disallow: /*/?s=* 这个就不用解释了,屏蔽捉取站内搜索结果。站内没出现这些链接不代表站外没有,如果收录了会造成和TAG等页面的内容相近。 6、Disallow: /?r=* 屏蔽留言链接插件留下的变形留言链接。(没安装相关插件当然不用这条指令) 7、Disallow: /*.jpg$ Disallow: /*.jpeg$ Disallow: /*.gif$ Disallow: /*.png$ Disallow: /*.bmp$ 屏蔽捉取任何图片文件,在这里主要是想节约点宽带,不同的网站管理员可以按照喜好和需要设置这几条指令。 8、Disallow: /?p=* 屏蔽捉取短链接。默认头部里的短链接,百度等搜索引擎蜘蛛会试图捉取,虽然最终短链接会301重定向到固定链接,但这样依然造成蜘蛛资源的浪费。 9、Disallow: /*/comment-page-* Disallow: /*?replytocom* 屏蔽捉取留言信息链接。一般不会收录到这样的链接,但为了节约蜘蛛资源,也屏蔽之。 10、Disallow: /a/date/ Disallow: /a/author/ Disallow: /a/category/ Disallow: /?p=*&preview=true Disallow: /?page_id=*&preview=true Disallow: /wp-login.php 屏蔽其他的一些形形色色的链接,避免造成重复内容和隐私问题。 10、Sitemap:http://***.com/sitemap.txt 网站地图地址指令,主流是txt和xml格式。告诉搜索引擎网站地图地址,方便搜索引擎捉取全站内容,当然你可以设置多个地图地址。要注意的就是Sitemap的S要用大写,地图地址也要用绝对地址。 上面的这些Disallow指令都不是强制要求的,可以按需写入。也建议站点开通谷歌管理员工具,检查站点的robots.txt是否规范。2023-07-25 11:03:571
请问怎么把robots.txt文件上传到网站根目录下?请详细解说!谢谢了!!!急!!!
1.用记事本建立一个robots.txt文件2.打开ftp软件.连接到网站的主机空间.3.点击robots.txt就可以上传了.ftp软件是用来上传下载的.主要有leapftp.cuteftp,flashfxp等等.2023-07-25 11:04:053
怎么把robots.txt文件放在网站根目录下?网站根目录是什么?在哪个位置?能详细一些吗
FTP登陆网站后,一般会有文件夹www,进入www文件夹(这才是网站的根目录,网站中可以访问的程序文件都要放在这个文件夹内),上传robots.txt到www文件夹内。为了形象说明,见附图:2023-07-25 11:04:123
不小心把ROBOTS.TXT设置成了禁止访问,应该怎么办
1,把robots.txt用txt打开,然后Disallow: /改成Disallow: 2,删除已有的sitemap.xml重新提交sitemap.xml2023-07-25 11:04:251
为什么最近我一点击太平洋电脑网上的链接迅雷就自动启动,下载一个“robots.txt” 的文件?
您好,点击链接之后迅雷就自动启动——这是因为你设置迅雷为你的默认下载工具。会下载一个“robots.txt”,可能是因为迅雷把跳转的那段代码当链接下载了。这不会影响到你的使用。 我这边测试了用Chrome浏览器,IE浏览器,猎豹浏览器均没有出现你说的情况。所以能否麻烦你给我描述下你的运行环境:操作系统,网络环境,使用的浏览器,具体访问地址,以便我为你提供更详细地解答。 至于如何能不出现下载“robots.txt”的提示,你可以尝试按住ctrl后点击左键打开链接。2023-07-25 11:04:323
怎样找到robots.txt这个文件夹,修改它
楼主您好:robots.txt它就像记事本一样的一个文件在网站的根目录下可以用ftp查看和修改 步骤为 点击虚拟空间或者服务器下的根目录 点击www或者web文件夹找到robots就可以进行修改了在网站后台的话若是dedecms的可以再文件管理器里面找到直接进行修改希望对您有所帮助。2023-07-25 11:04:392
什么是robots协议?网站中的robots.txt写法和作用
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。文件写法User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录Allow: /tmp 这里定义是允许爬寻tmp的整个目录Allow: .htm$ 仅允许访问以".htm"为后缀的URL。Allow: .gif$ 允许抓取网页和gif格式图片Sitemap: 网站地图 告诉爬虫这个页面是网站地图文件用法例1. 禁止所有搜索引擎访问网站的任何部分User-agent: *Disallow: /实例分析:淘宝网的 Robots.txt文件User-agent: BaiduspiderDisallow: /User-agent: baiduspiderDisallow: /很显然淘宝不允许百度的机器人访问其网站下其所有的目录。例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt” file)User-agent: *Allow: /例3. 禁止某个搜索引擎的访问User-agent: BadBotDisallow: /例4. 允许某个搜索引擎的访问User-agent: Baiduspiderallow:/例5.一个简单例子在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*.gif”这样的记录出现。User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Robot特殊参数:允许 Googlebot:如果您要拦截除Googlebot以外的所有漫游器不能访问您的网页,可以使用下列语法:User-agent:Disallow: /User-agent: GooglebotDisallow:Googlebot 跟随指向它自己的行,而不是指向所有漫游器的行。“Allow”扩展名:Googlebot 可识别称为“Allow”的 robots.txt 标准扩展名。其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。“Allow”行的作用原理完全与“Disallow”行一样。只需列出您要允许的目录或页面即可。您也可以同时使用“Disallow”和“Allow”。例如,要拦截子目录中某个页面之外的其他所有页面,可以使用下列条目:User-agent: GooglebotAllow: /folder1/myfile.htmlDisallow: /folder1/这些条目将拦截 folder1 目录内除 myfile.html 之外的所有页面。如果您要拦截 Googlebot 并允许 Google 的另一个漫游器(如 Googlebot-Mobile),可使用”Allow”规则允许该漫游器的访问。例如:User-agent: GooglebotDisallow: /User-agent: Googlebot-MobileAllow:使用 * 号匹配字符序列:您可使用星号 (*) 来匹配字符序列。例如,要拦截对所有以 private 开头的子目录的访问,可使用下列条目: User-Agent: GooglebotDisallow: /private*/要拦截对所有包含问号 (?) 的网址的访问,可使用下列条目:User-agent: *Disallow: /*?*使用 $ 匹配网址的结束字符您可使用 $字符指定与网址的结束字符进行匹配。例如,要拦截以 .asp 结尾的网址,可使用下列条目: User-agent: GooglebotDisallow: /*.asp$您可将此模式匹配与 Allow 指令配合使用。例如,如果 ? 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。但是,以 ? 结尾的网址可能是您要包含的网页版本。在此情况下,可对 robots.txt 文件进行如下设置:User-agent: *Allow: /*?$Disallow: /*?Disallow: / *?一行将拦截包含 ? 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (?),而后又是任意字符串的网址)。Allow: /*?$ 一行将允许包含任何以 ? 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (?),问号之后没有任何字符的网址)。尽管robots.txt已经存在很多年了,但是各大搜索引擎对它的解读都有细微差别。Google与百度都分别在自己的站长工具中提供了robots工具。如果您编写了robots.txt文件,建议您在这两个工具中都进行测试,因为这两者的解析实现确实有细微差别。2023-07-25 11:04:461
robots.txt可以删除吗
如果你想让搜索引擎收录站点的全部内容,robots.txt 文件是完全可以删除的。推荐用站点程序自带默认的内容就行(可以有效避免收录重复、后台敏感等内容)。PS:你可以不用删除,只保留网站地图这行设置内容就行了,有利于站点SEO。User-agent: *Sitemap: /sitemap.html2023-07-25 11:04:531
robots.txt 文件不写,是不是也可以?
robots.txt对搜索引擎来说是门,这扇门是否打开,哪些屋子的门没锁,哪些屋子的门锁了,你说的算。你不写robots.txt,就等于,你屋子没有门,搜索引擎可以任意进到哪间屋子2023-07-25 11:05:131
网站这个robots.txt要不要删?
这个可以删除的,这是一个协议,搜索引擎蜘蛛访问网站时查看的第一个文件,这个文件将会告诉蜘蛛哪些可以抓取索引,哪些不可以。百度官方建议,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。但是《SEO实战密码》一书中建议,就算允许抓取所有内容,也要建一个空的robots.txt文件,放在根目录下,因为有的服务器设置有问题,当robots文件不存在时会返回200状态码及一些错误信息,而不是404状态码,这可能使搜索引擎错误解读robots文件信息。2023-07-25 11:05:392
关于robots.txt被下载的问题!!!
首先,robots.txt是必须保证任何人、包括搜索引擎能访问的,否则就没有意义了,不能起到应有的作用。也可以这样说,只要搜索引擎能访问robots.txt,那任何人肯定也能访问。如果需要设置搜索引擎不允许访问“后台目录”、又不想让其他人看到后台目录(这是必须考虑到的!),假设后台目录是 /admin123/,那么我们可以在设置的时候这样写:User-agent: *Disallow: /adm关键在第二句,这样写就会阻止搜索引擎访问任何以“adm”开头的文件和目录。为了防止别人猜出你的后台目录,这里截取的越短越好,比如:User-agent: *Disallow: /a这样,同样起到作用,但留的字母更少,更难猜了,这时会阻止搜索引擎访问所有以“a”开头的文件和目录。这里需要注意一个问题,就是要避免影响其它的目录和文件,可以通过修改后台目录来实现,不要把别的需要收录的文件或目录一块给屏蔽了。不知这么解释你看懂了没有?一定要认真看下,不要浮躁2023-07-25 11:05:461
如何写网站robots.txt
robots.txt撰写方法:(1),允许所有的搜索引擎访问网站的所有部分或者建立一个空白的文本文档,命名为robots.txt。User-agent:*Disallow:或者User-agent:*Allow:/(2),禁止所有搜索引擎访问网站的所有部分。User-agent:*Disallow:/(3),禁止百度索引你的网站。User-agent:BaiduspiderDisallow:/(4),禁止Google索引你的网站。User-agent:GooglebotDisallow:/(5),禁止除百度以外的一切搜索引擎索引你的网站。User-agent:BaiduspiderDisallow:User-agent:*Disallow:/(6),禁止除Google以外的一切搜索引擎索引你的网站。User-agent:GooglebotDisallow:User-agent:*Disallow:/(7),禁止和允许搜索引擎访问某个目录,如:禁止访问admin目录;允许访问images目录。User-agent:*Disallow:/admin/Allow:/images/(8),禁止和允许搜索引擎访问某个后缀,如:禁止访问admin目录下所有php文件;允许访问asp文件。User-agent:*Disallow:/admin/*.php$Allow:/admin/*.asp$(9),禁止索引网站中所有的动态页面(这里限制的是有“?”的域名,如:index.php?id=8)。User-agent:*Disallow:/*?*2023-07-25 11:05:531
robots.txt不支持的代码有哪些
noindex。题目出自SEO面试试题中,robots.txt不支持的代码为noindex,支持Allow、Disallow和Crawl-delay。seo是一种缩写,它的全称是SeachEngineOptimization的简写,中文翻译过来就是搜索引擎优化。2023-07-25 11:06:001
网站下面没有robots.txt怎么办
新建一个文本文件重命名为robots.txt,然后通过ftp上传上去就行了,可以百度下robots的书写规则,然后自己定制一下就行,也可以用站长工具进行生成。很简单的。2023-07-25 11:06:072
怎么跳过robots.txt文件
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它[1]。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。百度官方建议,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放。但robots.txt不是命令,也不是防火墙,如同守门人无法阻止窃贼等恶意闯入者。功能 Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些链接。方便搜索引擎抓取网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。文件写法 User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符 Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录 Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录 Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录 Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。 Disallow: /** 禁止访问网站中所有包含问号 () 的网址 Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片 Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。 Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录 Allow: /tmp 这里定义是允许爬寻tmp的整个目录 Allow: .htm$ 仅允许访问以".htm"为后缀的URL。 Allow: .gif$ 允许抓取网页和gif格式图片 Sitemap: 网站地图 告诉爬虫这个页面是网站地图文件用法例1. 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 实例分析:淘宝网的 Robots.txt文件 User-agent: Baiduspider Disallow: / User-agent: baiduspider Disallow: / 很显然淘宝不允许百度的机器人访问其网站下其所有的目录。例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt” file) User-agent: * Allow: / 例3. 禁止某个搜索引擎的访问 User-agent: BadBot Disallow: / 例4. 允许某个搜索引擎的访问 User-agent: Baiduspider allow:/ 例5.一个简单例子在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。 User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*.gif”这样的记录出现。 User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ Robot特殊参数:允许 Googlebot:如果您要拦截除Googlebot以外的所有漫游器不能访问您的网页,可以使用下列语法: User-agent: Disallow: / User-agent: Googlebot Disallow: Googlebot 跟随指向它自己的行,而不是指向所有漫游器的行。 “Allow”扩展名: Googlebot 可识别称为“Allow”的 robots.txt 标准扩展名。其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。“Allow”行的作用原理完全与“Disallow”行一样。只需列出您要允许的目录或页面即可。您也可以同时使用“Disallow”和“Allow”。例如,要拦截子目录中某个页面之外的其他所有页面,可以使用下列条目: User-agent: Googlebot Allow: /folder1/myfile.html Disallow: /folder1/ 这些条目将拦截 folder1 目录内除 myfile.html 之外的所有页面。如果您要拦截 Googlebot 并允许 Google 的另一个漫游器(如 Googlebot-Mobile),可使用”Allow”规则允许该漫游器的访问。例如: User-agent: Googlebot Disallow: / User-agent: Googlebot-Mobile Allow: 使用 * 号匹配字符序列:您可使用星号 (*) 来匹配字符序列。例如,要拦截对所有以 private 开头的子目录的访问,可使用下列条目: User-Agent: Googlebot Disallow: /private*/ 要拦截对所有包含问号 () 的网址的访问,可使用下列条目: User-agent: * Disallow: /** 使用 $ 匹配网址的结束字符您可使用 $字符指定与网址的结束字符进行匹配。例如,要拦截以 .asp 结尾的网址,可使用下列条目: User-agent: Googlebot Disallow: /*.asp$ 您可将此模式匹配与 Allow 指令配合使用。例如,如果 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。但是,以 结尾的网址可能是您要包含的网页版本。在此情况下,可对 robots.txt 文件进行如下设置: User-agent: * Allow: /*$ Disallow: /* Disallow: / * 一行将拦截包含 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (),而后又是任意字符串的网址)。 Allow: /*$ 一行将允许包含任何以 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (),问号之后没有任何字符的网址)。尽管robots.txt已经存在很多年了,但是各大搜索引擎对它的解读都有细微差别。Google与百度都分别在自己的站长工具中提供了robots工具。如果您编写了robots.txt文件,建议您在这两个工具中都进行测试,因为这两者的解析实现确实有细微差别[1]。其它属性 1. Robot-version: 用来指定robot协议的版本号例子: Robot-version: Version 2.0 2.Crawl-delay:雅虎YST一个特定的扩展名,可以通过它对我们的抓取程序设定一个较低的抓取请求频率。您可以加入Crawl-delay:xx指示,其中,“XX”是指在crawler程序两次进入站点时,以秒为单位的最低延时。 3. Visit-time:只有在visit-time指定的时间段里,robot才可以访问指定的URL,否则不可访问. 例子: Visit-time: 0100-1300 #允许在凌晨1:00到13:00访问 4. Request-rate: 用来限制URL的读取频率例子: Request-rate: 40/1m 0100 - 0759 在1:00到07:59之间,以每分钟40次的频率进行访问 Request-rate: 12/1m 0800 - 1300 在8:00到13:00之间,以每分钟12次的频率进行访问标签 Robots.txt文件主要是限制整个站点或者目录的搜索引擎访问情况,而Robots Meta标签则主要是针对一个个具体的页面。和其他的META标签(如使用的语言、页面的描述、关键词等)一样,Robots Meta标签也是放在页面中,专门用来告诉搜索引擎ROBOTS如何抓取该页的内容。 Robots Meta标签中没有大小写之分,name=”Robots”表示所有的搜索引擎,可以针对某个具体搜索引擎写为name=”BaiduSpider”。content部分有四个指令选项:index、noindex、follow、nofollow,指令间以“,”分隔。 index指令告诉搜索机器人抓取该页面; follow指令表示搜索机器人可以沿着该页面上的链接继续抓取下去; Robots Meta标签的缺省值是index和follow,只有inktomi除外,对于它,缺省值是index、nofollow。注意事项上述的robots.txt和Robots Meta标签限制搜索引擎机器人(ROBOTS)抓取站点内容的办法只是一种规则,需要搜索引擎机器人的配合才行,并不是每个ROBOTS都遵守的。目前看来,绝大多数的搜索引擎机器人都遵守robots.txt的规则,而对于Robots META标签,支持的并不多,但是正在逐渐增加,如著名搜索引擎GOOGLE就完全支持,而且GOOGLE还增加了一个指令“archive”,可以限制GOOGLE是否保留网页快照。2023-07-25 11:06:231
网站robots.txt文件中这些内容是什么意思?
2. robots.txt语法收录协议写法1) 允许所有搜索引擎访问网站的所有部分robots.txt写法如下:User-agent: *Disallow:或者User-agent: *Allow: /注意: 1. 第一个英文要大写,冒号是英文状态下,冒号后面有一个空格,这几点一定不能写错。2) 禁止所有搜索引擎访问网站的所有部分robots.txt写法如下:User-agent: *Disallow: /3) 只需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引robots.txt写法如下:User-agent: *Disallow: /css/Disallow: /admin/Disallow: /images/收录协议写法注意:路径后面有斜杠和没有斜杠的区别:比如Disallow: /images/ 有斜杠是禁止抓取images整个文件夹,Disallow: /images 没有斜杠意思是凡是路径里面有/images关键词的都会被屏蔽4)屏蔽一个文件夹/templets,但是又能抓取其中一个文件的写法:/templets/mainrobots.txt写法如下:User-agent: *Disallow: /templetsAllow: /main5) 禁止访问html/目录下的所有以”.php”为后缀的URL(包含子目录)robots.txt写法如下:User-agent: *Disallow: html/*.php6) 仅允许访问某目录下某个后缀的文件,则使用“$”robots.txt写法如下:User-agent: *Allow: .html$Disallow: /7)禁止索引网站中所有的动态页面比如这里限制的是有“?”的域名,例如index.php?id=1robots.txt写法如下:User-agent: *Disallow: /*?*8) 禁止搜索引擎抓取我们网站上的所有图片(如果你的网站使用其他后缀的图片名称,在这里也可以直接添加)有些时候,我们为了节省服务器资源,需要禁止各类搜索引擎来索引我们网站上的图片,这里的办法除了使用“Disallow: /images/”这样的直接屏蔽文件夹的方式之外,还 可以采取直接屏蔽图片后缀名的方式。robots.txt写法如下:User-agent: *Disallow: .jpg$Disallow: .jpeg$Disallow: .gif$Disallow: .png$Disallow: .bmp$2023-07-25 11:06:432
robotstxt应该放在什么地方
robots.txt是要放到根目录下面的。所谓的根目录就是你的网站程序所在的那个目录,一般的根目录貌似都是个叫WEB或者www文件夹robots.txt文件必须驻留在域的根目录,并且必须命名为“robots.txt”。位于子目录中的robots.txt文件无效,因为漫游器只在域的根目录这个文件。如果您没有访问域的根目录,可以使用限制访问robots元标记。2023-07-25 11:06:551
robots.txt 允许收录网站所有页面 怎么写
User-agent: *Disallow:Allow: /2023-07-25 11:07:021
网站的robots.txt文件在哪
所谓的根目录就是你的网站程序所在的那个目录,一般的根目录貌似都是个叫WEB或者www文件夹robots.txt文件必须驻留在域的根目录,并且必须命名为“robots.txt”。位于子目录中的robots.txt文件无效,因为漫游器只在域的根目录这个文件。例如,http://www.baidu.com/robots.txt是有效位置。但是,http://www.baidu.com/mysite/robots.txt不是。2023-07-25 11:07:091
robots.txt 中 User-agent: * Disallow: /?r=* 以上是代表什么意思?
禁止索引蜘蛛抓取/?r=后面所有的页面!USer-agent为允许,*代表任意符2023-07-25 11:07:162
由于该网站的robots.txt文件存在限制指令,怎么办
robots.txt用于告知搜索引擎是否可以对站点进行索引如果robots.txt中屏蔽了某个搜索引擎的蜘蛛,而该搜索引擎又遵循robots协议,就不会抓取站点的内容,但robots协议并不是强制要求遵循的,没有法律效力简单的说就是网站不让搜索引擎抓取,而搜索引擎听话了,没有抓2023-07-25 11:07:242
robots.txt如何禁止百度搜索引擎抓取网站某个链接
应该是这样的,在ROBOTS.TXT文件里写入这些代码:User-agent: *Disallow:某个链接就可以了,望采纳!2023-07-25 11:07:442
Robots.txt文件是什么文件,可以删掉吗
可以删掉,这是规定搜索引擎的网页机器人的动作的文件。删除后就不限制机器人抓取你的网页,也就是说任何网页都能抓2023-07-25 11:07:511
某宝robots.txt是禁止别人抓取任何东西嘛?
是的,淘宝早就禁止百度抓取了。百度快照也会显示是禁止抓取的。2023-07-25 11:07:571
网站里的“robots”文件是什么意思?
搜索引擎爬去我们页面的工具叫做搜索引擎机器人,也生动的叫做“蜘蛛”蜘蛛在爬去网站页面之前,会先去访问网站根目录下面的一个文件,就是robots.txt。这个文件其实就是给“蜘蛛”的规则,如果没有这个文件,蜘蛛会认为你的网站同意全部抓取网页。Robots.txr文件是一个纯文本文件,可以告诉蜘蛛哪些页面可以爬取(收录),哪些页面不能爬取。举个例子:建立一个名为robots.txt的文本文件,然后输入User-agent: * 星号说明允许所有搜索引擎收录Disallow: index.php? 表示不允许收录以index.php?前缀的链接,比如index.php?=865Disallow: /tmp/ 表示不允许收录根目录下的tmp目录,包括目录下的文件,比如tmp/232.html2023-07-25 11:08:172
在robots 文件里怎么写入网站地图?
写法很简单的,首先一般是写在后面:User-agent: * Disallow: /plus/ad_js.phpDisallow: /plus/advancedsearch.phpDisallow: /plus/car.phpDisallow: /plus/carbuyaction.phpDisallow: /plus/shops_buyaction.phpDisallow: /plus/erraddsave.phpDisallow: /plus/posttocar.phpDisallow: /plus/disdls.phpDisallow: /plus/feedback_js.phpDisallow: /plus/mytag_js.phpDisallow: /plus/rss.phpDisallow: /plus/search.phpDisallow: /plus/recommend.phpDisallow: /plus/stow.phpDisallow: /plus/count.phpDisallow: /includeDisallow: /templetsSitemap: /http://www.wezhenxin.com/sitemap.txt这种写法,即可2023-07-25 11:08:252
robots.txt怎么写, 我只想让百度蜘蛛爬我的站
这样写: User-agent: BaiduspiderAllow: /User-agent: *Disallow: /2023-07-25 11:08:432
如何设置robots.txt禁止或只允许搜索引擎抓取特定目录?
蛑辉市聿糠肿ト 注意:网站的robots.txt文件一定要存放在网站的根目录。搜索引擎来网站抓取内容的时候,首先会访问你网站根目录下的一个文本文件robots.txt,搜索引擎机器人通过robots.txt里的说明,来理解该网站是否可以全部抓取,或只允许部分抓取。注意:网站的robots.txt文件一定要存放在网站的根目录。robots.txt文件举例说明禁止所有搜索引擎访问网站的任何内容User-agent: *Disallow: / 禁止所有搜索引擎抓取某些特定目录User-agent: *Disallow: /目录名1/Disallow: /目录名2/Disallow: /目录名3/ 允许访问特定目录中的部分urlUser-agent: *Allow: /158Allow: /joke 禁止访问网站中所有的动态页面User-agent: *Disallow: /*?*仅允许百度抓取网页和gif格式图片,不允许抓取其他格式图片User-agent: BaiduspiderAllow: /*.gif$Disallow: /*.jpg$Disallow: /*.jpeg$Disallow: /*.png$Disallow: /*.bmp$ 1.屏蔽404页面Disallow: /404.html 2.屏蔽死链原来在目录为/158下的所有链接,因为目录地址的改变,现在都变成死链接了,那么我们可以用robots.txt把他屏蔽掉。Disallow: /158/ 3.屏蔽动态的相似页面假设以下这两个链接,内容其实差不多。/XXX?123/123.html我们要屏掉/XXX?123 页面,代码如下:Disallow: /XXX? 4.告诉搜索引擎你的sitemap.xml地址具体代码如下:2023-07-25 11:08:522
怎么把robots.txt文件放在网站根目录下?网站根目录是什么?在哪个位置?能详细一些吗
FTP登陆网站后,一般会有文件夹www,进入www文件夹(这才是网站的根目录,网站中可以访问的程序文件都要放在这个文件夹内),上传robots.txt到www文件夹内。为了形象说明,见附图:2023-07-25 11:09:023
在网站robots的文件中想屏蔽PHP动态页面,怎么填写robots.txt文件
User-agent: *Disallow: /index.php?ac=frendid=001Disallow: /do.php?Disallow: /down.php?id=10242023-07-25 11:09:221
如何利用robots.txt对wordpress博客进行优化
一、先来普及下robots.txt的概念: robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不能被搜索引擎的漫游器获取的,哪些是可以被(漫游器)获取的。这个文件用于指定spider在您网站上的抓取范围,一定程度上保护站点的安全和隐私。同时也是网站优化利器,例如屏蔽捉取站点的重复内容页面。 robots.txt目前并不是一种标准,只是一种协议!所以现在很多搜索引擎对robots.txt里的指令参数都有不同的看待。 二、使用robots.txt需要注意的几点地方: 1、指令区分大小写,忽略未知指令,下图是本博客的robots.txt文件在Google管理员工具里的测试结果; 2、每一行代表一个指令,空白和隔行会被忽略; 3、“#”号后的字符参数会被忽略; 4、有独立User-agent的规则,会排除在通配“*”User agent的规则之外; 5、可以写入sitemap文件的链接,方便搜索引擎蜘蛛爬行整站内容。 6、尽量少用Allow指令,因为不同的搜索引擎对不同位置的Allow指令会有不同看待。 三、Wordpress的robots.txt优化设置 1、User-agent: * 一般博客的robots.txt指令设置都是面对所有spider程序,用通配符“*”即可。如果有独立User-agent的指令规则,尽量放在通配“*”User agent规则的上方。 2、Disallow: /wp-admin/ Disallow: /wp-content/ Disallow: /wp-includes/ 屏蔽spider捉取程序文件,同时也节约了搜索引擎蜘蛛资源。 3、Disallow: /*/trackback 每个默认的文章页面代码里,都有一段trackback的链接,如果不屏蔽让蜘蛛去捉取,网站会出现重复页面内容问题。 4、Disallow: /feed Disallow: /*/feed Disallow: /comments/feed 头部代码里的feed链接主要是提示浏览器用户可以订阅本站,而一般的站点都有RSS输出和网站地图,故屏蔽搜索引擎捉取这些链接,节约蜘蛛资源。 5、Disallow: /?s=* Disallow: /*/?s=* 这个就不用解释了,屏蔽捉取站内搜索结果。站内没出现这些链接不代表站外没有,如果收录了会造成和TAG等页面的内容相近。 6、Disallow: /?r=* 屏蔽留言链接插件留下的变形留言链接。(没安装相关插件当然不用这条指令) 7、Disallow: /*.jpg$ Disallow: /*.jpeg$ Disallow: /*.gif$ Disallow: /*.png$ Disallow: /*.bmp$ 屏蔽捉取任何图片文件,在这里主要是想节约点宽带,不同的网站管理员可以按照喜好和需要设置这几条指令。 8、Disallow: /?p=* 屏蔽捉取短链接。默认头部里的短链接,百度等搜索引擎蜘蛛会试图捉取,虽然最终短链接会301重定向到固定链接,但这样依然造成蜘蛛资源的浪费。 9、Disallow: /*/comment-page-* Disallow: /*?replytocom* 屏蔽捉取留言信息链接。一般不会收录到这样的链接,但为了节约蜘蛛资源,也屏蔽之。 10、Disallow: /a/date/ Disallow: /a/author/ Disallow: /a/category/ Disallow: /?p=*&preview=true Disallow: /?page_id=*&preview=true Disallow: /wp-login.php 屏蔽其他的一些形形色色的链接,避免造成重复内容和隐私问题。 10、Sitemap:http://***.com/sitemap.txt 网站地图地址指令,主流是txt和xml格式。告诉搜索引擎网站地图地址,方便搜索引擎捉取全站内容,当然你可以设置多个地图地址。要注意的就是Sitemap的S要用大写,地图地址也要用绝对地址。 上面的这些Disallow指令都不是强制要求的,可以按需写入。也建议站点开通谷歌管理员工具,检查站点的robots.txt是否规范。2023-07-25 11:09:291
robots.txt文件如果不设置又有什么影响呢
robots.txt仅仅是参考,很多不守规矩的网络爬虫不会去看。但是,从搜索引擎优化角度,还是要认真编写该文件,尤其你采用CMS建站,一个网页内容可以用不同的URL地址加不同参数查询到,这就造成了站内内容重复,搜索引擎会很反感,因为你浪费了网络爬虫的时间。所以,你需要用很多disallow将一些重复内容禁止掉。如果是隐私信息,用Disallow是没有用的,很多爬虫不遵守规矩,所以,不要将隐私开放在网站上。2023-07-25 11:09:373
Robots.txt如果为空对搜索殷勤有影响吗?
robots.txt很简单,是非常非常简单。有的人不懂robots是什么,有什么用? robots就是一个必须放在网站根目录、让搜索蜘蛛读取的txt文件,文件名必须是小写的"robots.txt"。通过robots.txt可以控制SE收录内容,告诉蜘蛛哪些文件和目录可以收录,哪些不可以收录。 在这里说明下,如果在网站目录下加了这个文件,搜索引擎会认为你是一个比较正规标准的站。 搜索引擎会对你有个好印象,我的论坛就有ROBOTS文件,有个前辈曾经还告诉过我,ROBOTS文件会对网站的关键词有影响,具体也没说的太清楚,例如我给我的学员用来做教程用的一个网站,ROBOTS文件是程序本来就带的,也没发现什么问题,更不用说对关键词有什么影响,切入整体,ROBOTS文件如何写! 用几个最常见的情况,直接举例说明: 1. 允许所有SE收录本站:robots.txt为空就可以,什么都不要写。 2. 禁止所有SE收录网站的某些目录: User-agent: * Disallow: /目录名1/ Disallow: /目录名2/ Disallow: /目录名3/ 3. 禁止某个SE收录本站,例如禁止百度: User-agent: Baiduspider Disallow: / 4. 禁止所有SE收录本站: User-agent: * Disallow: / 5. 加入sitemap.xml路径。 ROBOTS的潜力到底有多大?robots.txt很简单,是非常非常简单。有的人不懂robots是什么,有什么用? robots就是一个必须放在网站根目录、让搜索蜘蛛读取的txt文件,文件名必须是小写的"robots.txt"。通过robots.txt可以控制SE收录内容,告诉蜘蛛哪些文件和目录可以收录,哪些不可以收录。 在这里说明下,如果在网站目录下加了这个文件,搜索引擎会认为你是一个比较正规标准的站。 搜索引擎会对你有个好印象,我的论坛就有ROBOTS文件,有个前辈曾经还告诉过我,ROBOTS文件会对网站的关键词有影响,具体也没说的太清楚,例如我给我的学员用来做教程用的一个网站,ROBOTS文件是程序本来就带的,也没发现什么问题,更不用说对关键词有什么影响,切入整体,ROBOTS文件如何写! 用几个最常见的情况,直接举例说明: 1. 允许所有SE收录本站:robots.txt为空就可以,什么都不要写。 2. 禁止所有SE收录网站的某些目录: User-agent: * Disallow: /目录名1/ Disallow: /目录名2/ Disallow: /目录名3/ 3. 禁止某个SE收录本站,例如禁止百度: User-agent: Baiduspider Disallow: / 4. 禁止所有SE收录本站: User-agent: * Disallow: / 5. 加入sitemap.xml路径。 ROBOTS的潜力到底有多大?2023-07-25 11:09:581